oVirt¶
Siehe auch
GlusterFS
KVM
Proxmox
Einführung und Begriffe¶
oVirt-Engine 4.3¶
Das von Red Hat gesponserte Open-Source-Projekt oVirt (kommerzielle Variante: „RHV“ bzw. „RHEV“) vereint diverse bekannte Open-Source-Werkzeuge unter einer auf Java/JBoss basierenden Weboberfläche, mit der sich auch tausende virtuelle Maschinen erstellen und verwalten lassen. oVirt wurde 2011-12 unter einer Open-Source-Lizenz freigegeben, davor war oVirt nur eine gekürzte Community-Version von RHEV. Daher erschien oVirt in 2012-02 gleich zu RHEV passend in v3.0.
Das oVirt-Board besteht aus Red Hat, IBM und Caltech.
Der Artikel beschreibt Version 4 aufwärts.
- Cluster
Verbund aus Hosts gleichen CPU-Typs (Family), Storages und Netzwerken. Innerhalb eines Clusters können VMs hochverfügbar ausgelegt werden.
- Data Center
Enthält eine Sammlung von Clustern.
- DWH
oVirt Data Warehouse. Sammelt Nutzungs-Statistiken.
- EUS
Extended Update Support. 2 Jahre Full Support für die laufende Minor-Version.
- FSM
Finite State Machine
- Host
Ein Virtualisierungshost, Hypervisor, Pod, Node. Auf diesen läuft libvirt mit den VMs sowie VDSM.
- Hosted Engine
Virtuelle oVirt-Engine.
- NUMA
Non Uniform Memory Access
- oVirt-Engine
Management-Instanz, zentrale Komponente. Läuft als VM innerhalb der Virtualisierungsumgebung, oder ausserhalb (Bare Metal). Bietet ein vollständiges RESTful-Interface. Sie wird als „Hosted Engine“ bezeichnet (also auch die Kommandozeilenbefehle zur Engine), wenn sie selbst innerhalb der von ihr verwalteten Virtualisierungsinfrastruktur läuft.
- oVirt Guest Agents
In Python geschrieben; sollten in allen VMs installiert werden und führen die Befehle der oVirt-Engine und des VDSM (also des Hosts) aus. Dabei kommunizieren die Guest Agents über ein serielles VirtIO-Device mit dem VDSM. Die Hosts (nicht die oVirt-Engine) prüfen die „QEMU Guest Agents“ alle 5 Minuten auf Erreichbarkeit.
- OVN
Open Virtual Network
- OVS
Open vSwitch
- RHEV, RHV
Red Hat Enterprise Virtualization
- RHV-H
Red Hat Virtualization Hypervisor (Thin Host)
- RHV-M
Red Hat Virtualization Manager
- Self Hosted Engine
Damit wird die oVirt-Engine bezeichnet, die als Virtual Appliance / als VM im von ihr verwalteten oVirt-Cluster läuft (analog zu einer VMware vSphere-VM).
- SPM
Storage Pool Manager: nur ein Host ist Storage Pool Manager (SPM). Dieser kontrolliert den Zugriff auf den Storage, indem er die Metadaten unter den Storage Domains koordiniert. Beinhaltet das Erstellen, Löschen und Ändern von virtuellen Disks, Snapshots und Templates.
- VDSM
Virtual Desktop and Server Manager. Läuft nur auf den Hypervisor-Nodes; die oVirt-Engine führt ihre Befehle auf den Hosts mit Hilfe von VDSM aus. Kümmert sich beispielsweise auch darum, auf thin-provisioned VMs bei Bedarf deren Disks zu erweitern. Wird der vdmsd auf einem Power Managed Host neu gestartet, gilt der Host als non-responsive und wird durch die oVirt-Engine power-resettet. VDS ist der Vorgänger vom VDSM.
- Links
Homepage: https://www.ovirt.org/
Blog: https://blogs.ovirt.org/
Doku: https://ovirt.org/documentation/ und https://www.youtube.com/c/ovirtproject/videos
Doku RHEV 4.2: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.2/html/administration_guide/index
Doku RHEV 4.3: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.3/html/administration_guide/index
Doku RHEV 4.4: https://access.redhat.com/documentation/en-us/red_hat_virtualization/4.4/html/administration_guide/index
Download: https://ovirt.org/download/
Release Notes: https://ovirt.org/release/
Source Code: https://github.com/oVirt
Tipps
Im Umgang mit oVirt gilt ganz allgemein: Geduld haben und nicht nervös werden. Manche Dinge können auch mal gut und gerne 15 Minuten dauern.
Vor einem Reboot der oVirt-Engine unbedingt den „Global HA Maintenance“-Modus aktivieren, und nach dem Reboot wieder deaktivieren.
Die Web-Oberfläche der oVirt-Engine aktualisiert sich nur im gewünschten Intervall, wenn das Browser-Fenster auch den Fokus aufweist / aktiv ist.
oVirt bringt sein eigenes EPEL-Repo mit, weches aber nicht alles zur Verfügung stellt (
glances,iperfundinotifyfehlen beispielsweise).Wer oVirt per Ansible konfigurieren möchte, findet die Rollen hier: https://github.com/ovirt/ovirt-ansible-collection
Versionen¶
4.0.0: 20160623, benötigt CentOS 7.2.1511
4.1.0: 20170201, benötigt CentOS 7.3.1611
4.1.6: 20170918, benötigt CentOS 7.4.1708
4.2.2: 20180329, benötigt CentOS 7.4.1708
4.2.3: 20180504, benötigt CentOS 7.5.1804
4.2.8: 20190122, benötigt CentOS 7.6.1810
4.3.6: 20190926, benötigt CentOS 7.7.1908
4.3.10: 20200603, benötigt CentOS 7.8.2003
4.4.0: 20200520, benötigt CentOS 8.1.1911
4.4.1: 20200708, benötigt CentOS 8.2.2004
4.4.5: 20210204, benötigt CentOS 8.3.2011
oVirt 4.4 ist kein Minor-Release und müsste eigentlich oVirt 5.0 heissen, da neben CentOS 8 auch folgende Basis-Komponenten aktualisiert wurden:
Ansible 2.9
Gluster 7.7
WildFly 19
QEMU-KVM 4.2
Libvirt 6.0
Da es keinen Upgrade-Pfad von CentOS 7 hin zu 8 gibt, steht für oVirt 4.4 eine Neuinstallation an.
Hinweis
Die angegebene unterstütze CentOS-Version stammt aus den Release Notes und ist zwingend und maximal einzuhalten, was an den zahlreichen Komponenten und deren Versionsabhängigkeiten liegt. Beispielsweise wird das Einbinden eines CentOS 7.7-Hosts in oVirt 4.3.5 fehlschlagen.
oVirt wird in Zukunft auf CentOS Stream setzen: https://blogs.ovirt.org/2019/09/ovirt-and-centos-stream/
Ab Version 4.2 wird die Unterstützung für iptables-Firewalls als „deprecated“ gekennzeichnet, und ist seit 4.3 entfernt. Statt dessen kommt das in 4.2 unterstützte firewalld zum Einsatz.
Voraussetzungen¶
# >= dual core cpu?
lscpu | grep -i core
# virtualization supported?
grep -E '(vmx|svm)' /proc/cpuinfo
# 64 bit?
grep lm /proc/cpuinfo
# executable space protection supported?
grep nx /proc/cpuinfo
# >= 4 GB RAM?
free -m
# >= 100 GB disk space?
df -h
# Network at eth0 (your card) >= 1 Gbps?
ethtool eth0
Kompatibilitäts-Level¶
Welche oVirt-Hypervisor werden von welcher oVirt-Engine-Version unterstützt?
oVirt |
Hypervisor-Version |
|||||
|---|---|---|---|---|---|---|
Engine-Ver |
3.6 |
4.0 |
4.1 |
4.2 |
4.3 |
4.4 |
oVirt 4.0 |
x |
x |
||||
oVirt 4.1 |
x |
x |
x |
|||
oVirt 4.2 |
x |
x |
x |
x |
||
oVirt 4.3 |
x |
x |
x |
|||
oVirt 4.4 |
x |
|||||
Upgrade eines Hypervisors von einer Major-Version zur nächsten ist nicht möglich.
Nested Virtualization¶
oVirt lässt sich in einer Virtualisierungs-Infrastruktur wie KVM oder oVirt betreiben, wenn Nested Virtualization auf dem Host und CPU Passthrough in der VM aktiviert sind (VM > Edit > Host > Pass-Through Host CPU: on). Falls nicht, quittiert die Hosted Engine dies während des Setups mit dem Fehler „ERROR Host does not support domain type kvm for virtualization type ‚hvm‘ arch ‚x86_64‘“.
Installation¶
Lokale Admin-Workstation vorbereiten¶
Um die virtuellen Konsolen nutzen zu können, die das SPICE-Protokoll verwenden, einmalig auf den (Fedora)Admin-Stationen:
dnf -y install spice-xpi
Auf macOS verwendet man am besten Homebrew (Achtung, die Installation benötigt auf betagten Macs Stunden - mit Homebrew wird ein Mini-Linux im Home-Verzeichnis installiert):
# install brew; see also https://brew.sh/index
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew tap jeffreywildman/homebrew-virt-manager
brew install virt-viewer
# usage
remote-viewer path/to/console.vv
SPICE benötigt eine Freigabe auf Ports ab 5900 aufwärts (tcp). Es verwendet einen Port für die Kommunikationsaufnahme sowie einen für eine TLS-gesicherte Verbindung.
Host vorbereiten¶
Wer ein Hyperconverged-Setup fahren möchte, sollte zunächst Gluster einrichten. Für die Gluster-Nodes ist dann Bonding Mode 4 Pflicht.
Auf dem Host die zu oVirt maximale, passende CentOS-Version installieren und 64 GB Swap Space geben.
Version-Pinning für CentOS einrichten und CentOS updaten.
/etc/hosts-Datei aller Cluster-Member auf den gleichen Stand bringen - alle Hosts müssen dort aufgeführt seinDNS so anpassen, dass alle Hostnamen korrekt aufgelöst werden (Forward und Reverse)
Wie geht es der Maschine?
dmesg --reltime --level=emerg,alert,crit,err; dmesg --clearBonding: Switch vorbereiten - er muss den Host mit LACP sowie Jumbo-Frames unterstützen
Bonding: in CentOS den Bonding Mode 4 und Jumbo-Frames einrichten (802.3ad). Ab 4.3 bricht das oVirt-Setup ab, falls kein Bonding-Interface gefunden oder der Switch LACP-seitig nicht korrekt konfiguriert wurde. Der Name des Bonding-Interfaces muss
bond0und maximalbond9heissen.NTP mit Chrony einrichten
Sysctl: Swapiness auf „10“ setzen
EPEL-Repo deaktivieren, falls vorhanden
Die im Setup anzugebende Storage-Domain ist für die oVirt-Engine da und muss mindestens 41 GB freien Disk-Space haben. Sie erhält intern den Namen „hosted_storage“.
Das Ansible-Setup der oVirt-Engine prüft per getent ahostsv4 pod01.lf.local | grep pod01.lf.local, ob die Namensauflösung funktioniert. Daher sollte auch in der /etc/hosts-Datei der der FQDN vor dem Short-Name i angegeben werden.
oVirt-Engine installieren¶
Repo für oVirt 4.3
yum -y install http://resources.ovirt.org/pub/yum-repo/ovirt-release43.rpm
Um eine fixe Version der oVirt-Engine installieren zu können, dürfen die GlusterFS-Komponenten nicht aus den base-Repos stammen. Daher exclude=gluster* in /etc/yum.repos.d/CentOS-Base.repo eintragen. Dann:
yum list --showduplicates ovirt-hosted-engine-setup
yum install ovirt-hosted-engine-setup-2.2.16-1.el7.centos.noarch
yum list --showduplicates ovirt-engine-appliance
yum install ovirt-engine-appliance-4.2-20180329.1.el7.centos.noarch
Die oVirt-Engine Appliance soll später als „Hosted Engine“ betrieben werden:
yum -y install ovirt-hosted-engine-setup ovirt-engine-appliance
- oVirt 4.2-Setup:
Das Setup kennt zwei Modi, die sich leicht im Outfit und besonders in der Abfragereihenfolge der Setup-Informationen unterscheiden:
Das Python-basierte Setup (deprecated) verwendet otopi Python-Skripte aus
/usr/lib/python2.7/site-packages/otopi/.Ansible-basiertes Setup (die moderne Variante)
Es startet im Ansible-Modus. Wer das verhindern möchte, verwendet
hosted-engine --deploy --noansible
Achtung
oVirt 4.3.10-Setup: diverse Abbrüche bei hosted-engine --deploy
Das Setup bricht auch auf korrekt vorbereiteten Systemen mit ausreichend Ressourcen ab.
„network interface is not valid“:
[ INFO ] TASK [ovirt.hosted_engine_setup : Validate selected bridge interface if management bridge does not exists] [ ERROR ] fatal: [localhost]: FAILED! => {"changed": false, "msg": "The selected network interface is not valid"} [ ERROR ] Failed to execute stage 'Closing up': Failed executing ansible-playbook Hier steckt irgendein Logik-Fehler im Ansible-Setup: selbst wenn das Bonding-Interface korrekt konfiguriert wurde, geht es nicht weiter.„Fail if available memory is less then the minimal requirement“:
[ INFO ] TASK [ovirt.hosted_engine_setup : Fail if available memory is less then the minimal requirement] [ ERROR ] fatal: [localhost]: FAILED! => {"changed": false, "msg": "Available memory ( {'failed': False, 'changed': False, 'ansible_facts': {u'max_mem': u'46980'}}MB ) is less then the minimal requirement (4096MB). Be aware that 512MB is reserved for the host and cannot be allocated to the engine VM."} Glatt gelogen.Die naheliegende Abhilfe für beides - folgende Ansible-Variablen auf ihren gegenteiligen Wert setzen, also auf
/usr/share/ansible/roles/ovirt.hosted_engine_setup/defaults/main.yml¶# ovirt-hosted-engine-setup variables he_just_collect_network_interfaces: true # *** Do Not Use On Production Environment *** # ********** Used for testing ONLY *********** he_requirements_check_enabled: false he_memory_requirements_check_enabled: falsehilft auch nicht. Das Setup läuft erst durch, wenn vorher die „fail“-Direktiven durch „debug“ ausgetauscht werden:
cp /usr/share/ansible/roles/ovirt.hosted_engine_setup/tasks/pre_checks/001_validate_network_interfaces.yml /usr/share/ansible/roles/ovirt.hosted_engine_setup/tasks/pre_checks/001_validate_network_interfaces.yml.bak cp /usr/share/ansible/roles/ovirt.hosted_engine_setup/tasks/pre_checks/validate_memory_size.yml /usr/share/ansible/roles/ovirt.hosted_engine_setup/tasks/pre_checks/validate_memory_size.yml.bak sed --in-place 's/fail:/debug:/g' /usr/share/ansible/roles/ovirt.hosted_engine_setup/tasks/pre_checks/001_validate_network_interfaces.yml sed --in-place 's/fail:/debug:/g' /usr/share/ansible/roles/ovirt.hosted_engine_setup/tasks/pre_checks/validate_memory_size.yml
Wird NFS für die Storage-Domain der oVirt-Engine verwendet, vor dem Start des Setup mit vdsm-nfs-check.py noch dessen Benutzbarkeit testen.
Die Installation:
hosted-engine --deploy --help
hosted-engine --deploy
Deployment bricht ab, und man möchte nach der Lösung der Probleme dort weitermachen, wo man aufgehört hat?
hosted-engine --deploy --config-append=/var/lib/ovirt-hosted-engine-setup/answers/answers-20171130152127.conf
Deployment der Hosted Engine bricht ab, und man möchte ganz frisch starten, ohne das OS neu zu installieren?
ovirt-hosted-engine-cleanup
rm -rf /rhev/data-center/mnt/glusterSD/d113-pod01.ovirt.intra:_data1/*
rm -f ~/.ssh/known_hosts
Jetzt evtl. oVirt deinstallieren; möglicherweise Gluster-Volumes löschen und umorganisieren.
Host anpassen¶
- Multipath konfigurieren (gilt auch für alle weiteren hinzugefügten Hosts)
Wird Multipath nicht benötigt, nach der Aktivierung auf dem Host dieses Feature deaktivieren:
/etc/multipath.conf¶=> unbedingt in die zweite Zeile: # VDSM PRIVATE => ans Ende: # We do not have multiple paths to the storage, so in this case # we can disable Multipath blacklist { devnode "*" }
Test der Settings:
# this is a dry-run multipath -d -v3
Ein Reboot des Hosts ist nötig, damit die Multipath-Settings gesetzt werden.
- Datacenter und Cluster umbenennen:
Compute > Data Centers > Default: Edit > Datacenter Name: „Datacenter“
Compute > Clusters > Default: Edit > Cluster Name: „Cluster“
- Virtuelle Netzwerke einrichten
VLAN-IDs können von 0 bis 4094 vergeben werden.
- Weitere Hosts hinzufügen
Siehe Abschnitt „Host hinzufügen“.
- Storage konfigurieren
Die „Data“-Domain für die kommenden VMs konfigurieren.
Für einen bereits bestehenden Storage:
Storage > Domains > Import Domain
Data-Domain anklicken, Data Center > Attach > Datacenter > Ok. Ein paar Minuten Geduld, bis es aktiviert ist.
ISO- und Export-Domains (letztere werden seit oVirt 4.2 nicht mehr benötigt) können NFS- oder Gluster-basiert sein. Es kann nur eine ISO- und Export-Domain kann pro Datacenter aktiv sein.
ISO-Images in einer ISO-Storage-Domain ablegen:
cd /home/ovirt/.../images/111*/ wget any.iso chown vdsm:kvm any.iso
- Cluster
Auf den CPU-Type achten
Migration Policy: Minimal Downtime
Scheduling Policy: Optimize for Speed
- Templates
„Blank“-Template anpassen.
Cronjobs¶
Cronjobs auf einem reinen oVirt-Hypervisor werden nicht unbedingt benötigt. Die Sache sieht anders aus, wenn es sich um ein Hyperconverged Setup handelt - hier machen ein paar Cronjobs aus dem Gluster-Umfeld Sinn.
- Host
/usr/sbin/update-smart-drivedb 1> /dev/null /root/mail-gluster-heal-info
- oVirt-Engine
/usr/bin/engine-upgrade-check | /usr/bin/mail -s "ovirt-engine Upgrade Available" root /usr/bin/engine-backup --scope=all --mode=backup --file=/root/ovirt-engine-backup.$(date --iso-8601).tar --log=/root/ovirt-engine-backup.$(date --iso-8601).log 1> /dev/null cd /root; find -name "ovirt-engine-backup.*" -ctime +7 -exec rm {} \;
Storage Domains¶
Backup Storage Domains sind Data Domains mit dem Advanced Parameter „Backup“. Sie werden durch ein spezielles Icon in der Storage Domain-Liste gekennzeichnet.
Storage Domain entfernen / abhängen. Der Typ spielt dabei keine Rolle.
die Disks aller auf dieser Storage Domain laufenden VMs auf einen anderen Storage verschieben
Storage > Domains
Storage-Domain anklicken, Details anzeigen > Datacenter
Maintenance > OK
nach „Preparing for Maintenance“: Detach
nach „Detaching“: Storage > Stroage Domains > Storage auswählen > Remove
klappt das nicht, kann man „Destroy“ verwenden - mit diesem „Force Remove“ entfernt man alle Bezüge zum Storage aus der Datenbank der oVirt-Engine. Beim Remove wird der Storage aber so auch nicht aufgeräumt.
VM: Disk-Move von data-Domain 1 zu data-Domain 2¶
Man kann VM-disks moven, während die VM läuft; die VM bleibt dabei auch per SSH responsive. Ist die VM eingeschaltet, erstellt oVirt zunächst einen Snapshot der Maschine, der die Disk gehört, und führt nach dem Move die Differenzen auf dem Ziel-System zusammen. Aber: ich hatte am Morgen nach dem Move ein korruptes XFS der CentOS-VM. Maschinen, deren Disks im ausgeschalteten Zustand verschoben wurden, hatten das Problem nicht.
Die VM-Disk wird nach jedem Move um 1 bis 2 GByte grösser, egal ob bei ein- oder ausgeschalteter VM.
Move bedeutet wirklich Verschieben der Disks von Storage 1 auf Storage 2. Die Disk wird also am Quell-Ort gelöscht.
Es wird thin-provisioned verschoben. Man kann mit ca. 5 bis 7 GB/Minute (basierend auf Actual Size) Transferrate rechnen. Dauer einer 400 GB Disk, real 250 GB von Gluster auf NFS (10 Gbps): 35 Minuten.
Compute > Virtual Machines > auswählen > Disks > Move
VM: Sparsify Disks¶
Compute > Virtual Machines > Maschine auswählen
VM runterfahren
Details anzeigen > Disks > More > Sparsify
Dauert ca. 1 Minute.
Gluster¶
oVirt bringt die eigene passende GlusterFS-Version mit. Für ein Hyperconverged-Setup Gluster aus dem oVirt-Repo vor der eigentlichen oVirt-Installation aufsetzen und konfigurieren.
Bis v4.2.7 konnte man die ovirt-engine in der gleichen Storage-Domain wie die VMs laufen lassen, danach benötigt sie selbst ein „hosted_storage“ Gluster-Volume mit mind 74 GB Grösse. Ignoriert man dies, lässt sich das Datacenter nicht aktivieren. Ein Import der Storage Domain, auf der die Hosted Engine läuft, um sie für VMs nutzen zu können, klappt nicht.
Es gilt:
Es muss mit Replica 3 gearbeitet werden.
Replica 3 Arbiter 1 ist effizienter im Umgang mit Disk-Ressourcen, kostet aber mehr Rechenaufwand (besonders beim Healing).
In einer Gluster-basierten Storage-Domain sind keine Sharable Disks möglich.
oVirt wünscht sich spezielle Gluster-Optimierungen:
gluster volume set hosted_storage cluster.data-self-heal-algorithm full # default: (null)
gluster volume set hosted_storage features.shard on # default: off
gluster volume set hosted_storage features.shard-block-size 64MB # default: 64MB
gluster volume set hosted_storage group virt # default: gibt es nicht
gluster volume set hosted_storage network.ping-timeout 10 # default: 42
gluster volume set hosted_storage network.remote-dio off # default: off
gluster volume set hosted_storage performance.low-prio-threads 32 # default: 16
gluster volume set hosted_storage performance.strict-o-direct on # default: off
gluster volume set hosted_storage storage.owner-gid 36 # default: -1
gluster volume set hosted_storage storage.owner-uid 36 # default: -1
NFS¶
Tipp
NFS-Shares, die durch oVirt genutzt werden, performen bis zu 10x schneller, wenn sie - als Beispiel auf einer Synology - ohne Data Checksum Calculation (für Datenintegrität) sowie ohne File Compression konfiguriert werden.
Ein Reboot des NFS-Servers macht oVirt nichts aus, solange dort keine Data Storage Domain gemountet ist, auf der VMs laufen.
NFS-Server für die Storage-Domains hosted_storage, Data, Export oder ISO verwenden - so muss der NFS-Server konfiguriert werden.
groupadd kvm --gid 36
useradd vdsm --uid 36 --gid kvm
mkdir -p /data/ovirt/{hosted_storage,data,export,isos}
chmod 0755 /data/ovirt/{hosted_storage,data,export,isos}
chown 36:36 /data/ovirt/{hosted_storage,data,export,isos}
setsebool -P virt_use_nfs on
/data/ovirt/hosted_storage host1(rw) host2(rw) host3(rw)
/data/ovirt/data host1(rw) host2(rw) host3(rw)
/data/ovirt/export host1(rw) host2(rw) host3(rw)
/data/ovirt/isos host1(rw) host2(rw) host3(rw)
yum -y install nfs-utils
systemctl enable rpcbind
systemctl enable nfs-server
systemctl start rpcbind
systemctl start nfs-server
# or
exportfs -rv
showmount --exports
Ob der Storage korrekt konfiguriert und für oVirt verwendbar ist, lässt sich auf einem Host mit folgendem Python-Skript testen:
curl --output /root/vdsm-nfs-check.py https://raw.githubusercontent.com/oVirt/vdsm/master/contrib/nfs-check.py
python /root/vdsm-nfs-check.py 10.80.32.58:/data/ovirt/hosted_storage
Auf einem produktiven oVirt-Host niemals systemctl stop rpcbind ausführen. Damit werden alle Storages abgehängt und der Host unresponsive.
Siehe auch https://www.ovirt.org/develop/troubleshooting-nfs-storage-issues.html
Administration¶
oVirt-Engine¶
- Statusabfrage
hosted-engine --vm-status- Engine herunterfahren
Vorher in den Global Maintenance Mode wechseln. Dann am sichersten auf dem Host ausführen, auf dem die oVirt-Engine läuft:
hosted-engine --vm-shutdownDie VMs laufen ungestört weiter, werden dann aber nicht mehr in Bezug auf Hochverfügbarkeit, Live Migration etc. koordiniert.
- Engine hochfahren
Einfach den Global Maintenance Mode abschalten (auf dem Host, auf dem sie nachher auch laufen soll).
Alternativ auf dem Host ausführen, auf dem sie nachher auch laufen soll:
hosted-engine --vm-startAnschliessend den Global Maintenance Mode abschalten.
- Backup erstellen
Engine-Backups sollten täglich laufen, da sich oVirt sonst 48h nach dem letzten Backup per Alert in der Event List beschwert, dass das Backup zu alt ist.
Manuell ein Backup erstellen:
/usr/bin/engine-backup --scope=all --mode=backup --file=/root/ovirt-engine-backup.$(date --iso-8601).tar --log=/root/ovirt-engine-backup.$(date --iso-8601).log
Automatisierte Backups der oVirt-Engine inkl. PostgreSQL-DBs in der Engine selbst einrichten, und nur die letzten 8 Backups behalten:
/usr/bin/engine-backup --scope=all --mode=backup --file=/root/ovirt-engine-backup.$(date --iso-8601).tar --log=/root/ovirt-engine-backup.$(date --iso-8601).log cd /root; find -name "ovirt-engine-backup.*" -ctime +7 -exec rm {} \;
- Engine aus älterem Backup wiederherstellen
# on a host hosted-engine --set-maintenance --mode=global # in ovirt-engine engine-cleanup engine-backup --mode=restore --file=ovirt-engine-backup.tar --log=ovirt-restore.log --provision-all-databases --restore-permissions engine-setup --offline # on a host hosted-engine --set-maintenance --mode=none
- Neue Engine aus Backup wiederherstellen
Datei
/etc/hostsprüfen. Dann:yum install http://resources.ovirt.org/pub/yum-repo/ovirt-release43.rpm yum -y install ovirt-engine # in ovirt-engine engine-backup --mode=restore --file=ovirt-engine-backup.tar --log=ovirt-restore.log --provision-all-databases --restore-permissions engine-setup
- PostgreSQL konfigurieren
Zugriff auf PostgreSQL erlauben.
/var/opt/rh/rh-postgresql95/lib/pgsql/data/pg_hba.conf¶host all all 10.199.26.0/24 md5
su - postgres systemctl restart postgresql
Anzahl Connections von 150 auf 300 erhöhen:
/var/opt/rh/rh-postgresql95/lib/pgsql/data/postgresql.conf¶max_connections=300
Hosted Engine neu starten.
- Mit PostgreSQL direkt arbeiten, um z.B. die Datenbank zu importieren
# on a host hosted-engine --set-maintenance --mode=global # in ovirt-engine systemctl stop ovirt-engine su - postgres -c 'scl enable rh-postgresql95 -- psql'
- PostgreSQL - Verbindungen killen und Datenbanken löschen
postgres=# revoke connect on database engine from public, engine; select pg_terminate_backend(pid) from pg_stat_activity where pid <> pg_backend_pid() and datname = 'engine'; postgres=# drop database engine; postgres=# drop user engine; postgres=# revoke connect on database ovirt_engine_history from public, ovirt_engine_history; select pg_terminate_backend(pid) from pg_stat_activity where pid <> pg_backend_pid() and datname = 'ovirt_engine_history'; postgres=# drop database ovirt_engine_history; postgres=# drop user ovirt_engine_history;
- Zertifikat verlängern (
sun.security.validator.ValidatorException: PKIX path validation failed: java.security.cert.CertPathValidatorException: validity check failedim WebGUI) # on a host hosted-engine --set-maintenance --mode=global # wait for „state=GlobalMaintenance“ for all hosts, and „!! Cluster is in GLOBAL MAINTENANCE mode !!“ hosted-engine --vm-status # in ovirt-engine engine-setup --offline # Do you want Setup to configure the firewall? (Yes, No) [Yes]: no # Would you like to backup the existing database before upgrading it? (Yes, No) [Yes]: yes # Perform full vacuum on the oVirt engine history database ovirt_engine_history@localhost? (Yes, No) [No]: no # Perform full vacuum on the engine database engine@localhost? (Yes, No) [No]: no # Renew certificates? (Yes, No) [No]: yes # Renew certificates? (Yes, No) [No]: yes # During execution engine service will be stopped (OK, Cancel) [OK]: ok # --== CONFIGURATION PREVIEW ==-- # Default SAN wipe after delete : False # Firewall manager : firewalld # Update Firewall : False # Host FQDN : ovirt-engine.example.com # Engine database secured connection : False # Engine database user name : engine # Engine database name : engine # Engine database host : localhost # Engine database port : 5432 # Engine database host name validation : False # Engine installation : True # PKI organization : example.com # Renew PKI : True # Set up ovirt-provider-ovn : True # Configure WebSocket Proxy : True # DWH installation : True # DWH database secured connection : False # DWH database host : localhost # DWH database user name : ovirt_engine_history # DWH database name : ovirt_engine_history # Backup DWH database : True # DWH database port : 5432 # DWH database host name validation : False # Configure Image I/O Proxy : True # Configure VMConsole Proxy : True # Please confirm installation settings (OK, Cancel) [OK]: ok # on a host hosted-engine --vm-status hosted-engine --set-maintenance --mode=none # after ~3 mins, should be „detail“: „Up“ hosted-engine --vm-status
Die Bedeutung der Icons in der List-Ansicht der Virtual Machines:
blauer Halbmond: VM suspended
graues Schloss: VM locked
graues, nach oben ziehendes Dreieck: Wait for Launch
grüner runder Pfeil: Reboot in Progress
grünes Dreieck mit blauem Zahnrad: VM run once
grünes Dreieck mit weissem Pfeil: VM Migration
grünes Dreieck: VM running
grünes, nach oben ziehendes Dreieck: VM starting
rotes Dreieck: VM down
rotes, nach unten ziehendes Dreieck: VM stopping
Sanduhr: Wait
Hosted Engine: Disk moven¶
Die Disks der Hosted-Engine lassen sich nicht einfach so auf eine andere Storage-Domain moven. Hier muss die Engine mittels Backup/Restore neu installiert werden. Der Ablauf ist eigentlich simpel, es dauert einfach.
Zunächst den Namen des Datacenters, des Clusters und des Hosts notieren, auf dem die Engine läuft („HE-Host“). Sicherstellen, dass die VMs in der Zeit nicht HA-seitig floaten, oder alle VMs bis auf die Hosted-Engine herunterfahren.
Anschliessend im Blank Template den Punkt „High Availability“ abschalten - sonst wird das Deployment der neuen oVirt-Engine fehlschlagen.
Danach auf dem HE-Host:
hosted-engine --set-maintenance --mode=global
In der Engine selbst:
systemctl stop ovirt-engine
systemctl disable ovirt-engine
/usr/bin/engine-backup --scope=all --mode=backup --file=/root/ovirt-engine-backup.$(date --iso-8601).tar --log=/root/ovirt-engine-backup.$(date --iso-8601).log
scp -p /root/ovirt-engine-backup* host:/root/
Auf dem Host:
hosted-engine --vm-shutdown
systemctl enable firewalld
systemctl start firewalld
hosted-engine --deploy --restore-from-file=/root/ovirt-engine-backup.tar
Das Setup stellt die üblichen Fragen, einige sind jedoch neu. Darauf achten, für das Datacenter und den Cluster die bisherigen Namen zu verwenden:
Please enter the name of the datacenter where you want to deploy this hosted-engine host. Please note that if you are restoring a backup that contains info about other hosted-engine hosts,
this value should exactly match the value used in the environment you are going to restore. [Default]: Datacenter
Please enter the name of the cluster where you want to deploy this hosted-engine host. Please note that if you are restoring a backup that contains info about other hosted-engine hosts,
this value should exactly match the value used in the environment you are going to restore. [Default]: Cluster
Renew engine CA on restore if needed? Please notice that if you choose Yes, all hosts will have to be later manually reinstalled from the engine. (Yes, No)[No]:
Pause the execution after adding this host to the engine?
You will be able to iteratively connect to the restored engine in order to manually review and remediate its configuration before proceeding with the deployment:
please ensure that all the datacenter hosts and storage domain are listed as up or in maintenance mode before proceeding.
This is normally not required when restoring an up to date and coherent backup. (Yes, No)[No]:
Jetzt:
Geduld haben. Am Ende lässt sich der neue Storage angeben.
Der Maintenance Mode wird automatisch verlassen.
Ist die Hosted Engine aktiv, müssen nun noch alle anderen HE-Hosts neu installiert werden, damit sie ihre Storage-Konfiguration aktualisieren. Host für Host muss in den Maintenance Mode versetzt und mit Klick auf „Reinstall“ plus „DEPLOY“ im Hosted-Engine-Tab re-installiert werden.
Durch die Neuinstallation ändert sich möglicherweise auch der SSH-Key der Hosted Engine. Auf den Hosts dann also die
authorized_keysanpassen.Anschliessend im Blank-Template „High Availability“ wieder aktivieren.
„hosted_storage_old*“ kann gelöscht werden.
Cronjobs in der oVirt-Engine neu einrichten.
Geht im Deployment irgendetwas schief, kann man
den
ovirt-ha-agentauf einem Host neu starten, damit der Shared Storage wieder zur Verfügung stehtden Global Maintenance Mode beenden
per SSH auf die oVirt-Engine einloggen
systemctl enable ovirt-engine; systemctl start ovirt-engineins oVirt-GUI einloggen
die Ursache fixen
das Fragment „external-HostedEngineLocal“ stoppen und entfernen
den neuen hosted_storage aufräumen
es erneut probieren
Cluster¶
Der Host mit der ältesten Hardware im Cluster bestimmt dessen „CPU Type“, z.B. „Intel Haswell-noTSX Family“. (CentOS-)VMs weisen diesen auch über lscpu aus. Wird ein älterer Host entfernt und die „CPU Type“ im Cluster z.B. auf „Intel Broadwell Family“ hochkonfiguriert, wird das von laufenden VMs nicht erkannt, auch nicht nach deren Restarts
- das gelingt erst nach dem Reboot aller Hosts im Cluster.
Ist der voreingestellte CPU-Typ höher als der für einen neu hinzugefügten Host (hinzugefügter Host hat älteren CPU-Type), wird der neue Host als „non-operational“ angezeigt. Wird dann der CPU-Typ im Cluster nachträglich runtergeschraubt, was optisch funktioniert, können VMs nicht auf die älteren Hosts migriert werden.
In oVirt 4.3 klappt es für VMs, die abgeschaltet und wieder eingeschaltet werden, ein Reboot genügt nicht. Falls es überhaupt nicht klappt, hilft laut Foren (ungetestet):
Anzahl der CPU-Cores für die oVirt-Engine ändern, damit ein OVF_STORE-Update getriggert wird
Global Maintenance Mode aktivieren
oVirt-Engine rebooten
High Availability (HA)¶
In einem Cluster-Verbund kann die oVirt-Engine auf jedem dafür geeigneten Host ausgeführt werden (empfohlen sind aber maximal sieben dafür ausgelegte Hosts). Ist der Host passend dafür installiert worden (bei der Aufnahme des Hosts in den Cluster „Deploy Hosted Engine: yes“), läuft ein HA-Agent, der ständig prüft, ob die oVirt-Engine antwortet.
Sollte der Host, der die Hosted Engine aktuell ausführt, mal nicht so schnell antworten, wird das von allen anderen Hosts bzw. deren HA-Agents bemerkt. Es versuchen dann alle von sich aus, die oVirt-Engine zu starten. Die FSM des HA-Agents vermerkt dann:
Engine ist auf diesem Host down (EngineStop-EngineDown.)
Engine bitte starten (EngineDown-EngineStart.)
Engine startet (EngineStart-EngineStarting.)
Im ganzen Cluster-Verbund kann es allerdings nur einen Host geben, der die Engine ausführen darf. Sobald die HA-Agents bemerken, dass die Engine wieder (woanders) ausgeführt wird, setzen sie ihre FSM zurück:
forciertes Engine Stop
FSM re-initialisieren
markieren, dass Engine auf diesem Host down ist
Dieser Prozess sorgt für eine ganze Reihe an „ovirt-hosted-engine state transition“-Nachrichten. Nur der Host, der die Engine am Ende ausführt, meldet sich nicht per Mail.
Dieses Verhalten ist übrigens auch der Grund, warum es nach einem hosted-engine --set-maintenance --mode=global; hosted-engine --vm-shutdown und einem anschliessenden hosted-engine --set-maintenance --mode=none kein hosted-engine --vm-start braucht - die HA-Agents kümmern sich um das Hochfahren der Engine.
Die States der FSM in der Übersicht:
StartState > ReinitializeFSM
> EngineDown
> EngineStarting
EngineStart > EngineStarting
EngineStarting
> EngineMaybeAway > EngineUnexpectedlyDown > EngineDown > EngineStart
> EngineUp > EngineStop > EngineDown > EngineStart
> EngineForceStop
> EngineDown > EngineStart
> ReinitializeFSM
Hosts¶
- Kann man auf einem Host einfach
systemctl restart networkausführen, wenn er die oVirt-Engine ausführt und gleichzeitig Gluster-Member ist? Nicht zu empfehlen, obwohl das erst einmal tatsächlich klappt. Die oVirt-Engine pausiert evtl. einige VMs, meldet
Reconstructing master domain on Data Center ...undActivating Host ..., und aktiviert die VMs wieder.Danach gibt es allerdings das Problem, dass man sich nicht mehr per SPICE zur virtuellen Konsole der VMs verbinden kann - auch ein Neustart der Hosted-Engine hilft nicht. Ein Reboot des ganzen Systems hilft dem System wieder auf die Beine (Achtung: der Reconstruct der Storage Domains dauert ewig).
VM: Hotplugging¶
CPU: funktioniert für CentOS-VMs ohne Reboot (up und downsizing).
Memory Upsizing: funktioniert nur in Schritten, die durch 256MB teilbar sind. Beispiel: 1003 MB > 1259mb, 1515mb etc. Geht maximal 16 mal ohne Neustart.
Memory Downsizing: nur mit Reboot der VM möglich.
VM: Live-Migration / Backup¶
Früher hiess es, man müsste die Einstellung migration_max_bandwidth in /etc/vdsm/vdsm.conf anpassen, um die genutzte Bandbreite bei einer (Memory-? Disk-?)Migration zu erhöhen. Siehe https://access.redhat.com/solutions/108813
Heute wird das in der Engine per „Compute > Cluster > Migration Policy: Bandwith in Mbps“ konfiguriert.
Der Wert „Auto“ sollte angepasst werden, da er in einem 10 Gbps-Netzwerk den Durchsatz auf 1 Gpbs begrenzt.
Benutzerverwaltung¶
- Benutzer hinzufügen:
ovirt-aaa-jdbc-tool user add myuser --attribute=firstName=My --attribute=lastName=User --attribute=email=myuser@linuxfabrik.ch # Note: by default created user cannot log in. see: # /usr/bin/ovirt-aaa-jdbc-tool user password-reset --help. ovirt-aaa-jdbc-tool user password-reset myuser --password-valid-to="2025-08-01 12:00:00-0800" --force ovirt-aaa-jdbc-tool user show myuser ovirt-aaa-jdbc-tool settings show
Anschliessend in der Web-Oberfläche der oVirt-Engine unter Administration > Users > User anklicken > Permissions die Role „SuperUser“ hinzufügen. Ohne zugewiesene Rolle kann sich der Benutzer nicht einloggen.
- Read-only Benutzer benötigt? Im oVirt WebGUI:
Administration > Configure > System Permissions > Add
Benutzer suchen und auswählen
„Role to Assign“ auf „ReadOnlyAdmin“ setzen
Mit „Ok“ die Änderungen übernehmen
Siehe auch https://access.redhat.com/solutions/3245091
Deployment¶
Host hinzufügen¶
Der oVirt-Engine sollte man ca. 10 Minuten Zeit geben, einen Host hinzuzufügen. Beobachten kann man dies auf den hinzuzufügenden Hosts per tail -f /var/log/messages /var/log/yum.log. Hat keinen Einfluss auf den laufenden Betrieb, kann also jederzeit durchgeführt werden.
Achtung
Fieser Bug in oVirt 4.2.2: Ein neuer Host lässt sich nicht über das GUI hinzufügen. Es scheitert an der Erstellung der Netze - der Host bleibt ständig in einer Schleife „Activating - Non-Operational - Activating - …“ hängen. Daher unbedingt vor dem Deploy unter Compute > Cluster > Logical Networks > Button: Manage Networks alle Netze auf „nicht required“ setzen (bis auf oVirt Management - dieses nicht). Nach Hinweis aus https://lists.ovirt.org/pipermail/users/2018-April/088430.html Danach weiter.
Ablauf:
SSH-Key der oVirt-Engine auf dem neuen Host eintragen.
In der oVirt-Engine per Klick den Host in oVirt aufnehmen. Darauf achten:
Authentication mit SSH Public Key wählen
„Automatically configure Host Firewall“ abschalten (wenn sie bereits konfiguriert wurde)
„oVirt-Engine“: deploy (damit ist der Host in der Lage, die oVirt-Engine auszuführen)
Wird Multipath nicht benötigt, nach der Aktivierung auf dem Host dieses Feature deaktivieren:
=> unbedingt in die zweite Zeile:
# VDSM PRIVATE
=> ans Ende:
# We do not have multiple paths to the storage, so in this case
# we can disable Multipath
blacklist {
devnode "*"
}
Test der Settings:
multipath -d -v3
Netze attachen:
Compute > Hosts > Network Interfaces > Setup Host Networks: alle Netze auf das Bonding-Interface des Hosts ziehen.
Compute > Cluster > Logical Networks > Button: Manage Networks: alle Netze wieder auf „required“ setzen (falls oVirt 4.2.2).
Letzte Tests, bevor VMs auf die Maschine kommen:
über das oVirt-GUI: Set Host in „Maintenance Mode“, Reboot Host und Re-Activate
Schauen, ob
lsblkstimmt,systemctl status firewalldmuss laufen und alles nötige zulassen.cronjobs aktivieren
Danach können VMs auf die Maschine.
VM per Kickstart¶
Für oVirt muss am Ende des Kickstarts ein „shutdown“ durchgeführt werden, sonst wird das ISO-File nicht aus dem virtuellen CD-ROM ausgeworfen.
oVirt-Guest-Tools¶
So installiert man den oVirt Guest-Agent.
CentOS 7:
yum -y install http://resources.ovirt.org/pub/yum-repo/ovirt-release43.rpm
yum -y install ovirt-guest-agent
systemctl enable --now ovirt-guest-agent
yum -y install spice-vdagent
systemctl enable spice-vdagentd
systemctl start spice-vdagentd
CentOS 8, Fedora, Ubuntu 20+:
yum -y install qemu-guest-agent
systemctl enable --now qemu-guest-agent
yum -y install spice-vdagent
systemctl enable spice-vdagentd
systemctl start spice-vdagentd
VirtIO-Treiber und Windows-VMs¶
Die VirtIO Windows-Treiber ISO-Dateien installieren (landen in /usr/share/virtio-win):
yum -y install virtio-win
Wer eine ISO-Storage-Domain verwendet, kann die ISO-Files linken:
ln -s /usr/share/virtio-win/virtio-win.iso /data/ovirt/isos/*/images/11111111*/
Wer downloaden möchte, kann sich auf https://resources.ovirt.org/pub/ovirt-$VER/iso/oVirt-toolsSetup/ umsehen.
Anschliessend in der Windows-Maschine die CD einlegen. Die Treiber werden per virtio-win-gt-x64 installiert, die oVirt Guest-Tools über den Aufruf von guest-agent/qemu-ga-x86_64.
Trick: Während der Windows-Installation CD auf die Treiber-CD wechseln, und die Treiber für „virtioscsi“-Disk laden. Danach wieder die OS-CD einlegen.
Snapshots¶
Die Snapshot-Funktion findet sich unter Compute > Virtual Machines > VM auswählen > Tab: Snapshots.
Snapshot-Hierarchie¶
Im Beispiel wurden vier Snapshots einer VM erstellt. Der neueste/zuletzt erstellte Snapshot findet sich als erstes in der Liste.:
Active VM State
+--- snapshot 4
+--- snapshot 3
+--- snapshot 2
+--- snapshot 1
Snapshots eines Snapshots sind nicht möglich, es gibt nur eine lineare Snapshot-Historie.
Snapshot erstellen¶
Es empfiehlt sich, die VM abzuschalten. Werden Snapshots einer laufenden Maschine erzeugt, hängt die Konsistenz eines Snapshots davon ab, ob die oVirt Guest Agents installiert sind. Bei Datenbank-Servern ist das Abschalten generell zu empfehlen.
Oben rechts den Button „Create Snapshot“ oder im Snapshot-Tab den Button „Create“ wählen.
„Description“ angeben (Pflichtfeld), z.B. „initial VM after fresh installation“, und bevor mit weiteren Tasks fortgefahren wird
„Disks to include“ auswählen (Disks sind vorausgewählt)
„Save Memory“ gibt an, ob auch der Zustand des Hauptspeichers übernommen werden soll. Falls das gewählt wird, wird eine laufende VM während des Snapshottings kurz pausiert.
Die Erstellung eines Snapshots kann auf lahmen oder beanspruchten Systemen auch bei minimalen VMs 1 bis 2 Minuten benötigen. Keine Angst: die VM läuft anschliessend nicht in einem Snapshot-Modus, sondern weiter wie bisher. Auch bei vorhandenen Snapshots startet eine VM daher immer vom State „Active VM“. Die Snapshots liegen also quasi auf Halde.
VM vom ausgewählten Snapshot starten¶
Um von einem bestimmten Snapshot zu starten oder dauerhaft auf diesen zurückzukehren, ist das Abschalten der VM Pflicht, sonst lassen sich die nachfolgend beschriebenen Buttons nicht nutzen.
Im Snapshot-Tab den gewünschten Snapshot auswählen.
Den Button „Preview“ wählen (und warten). Wer mehr Einfluss nehmen möchte, wählt den Drop-Down neben „Preview“ und dann „Custom“. Egal wie: Der Status wechselt auf IN_PREVIEW, der derzeit „aktive“ Snapshot erhält das „Auge“-Icon.
Wer möchte, kann per „Run“-Button die VM im mit „Preview“ gewählten Snapshot starten.
Im Preview-Mode lassen sich jetzt nur noch zwei Buttons wählen:
der „Undo“-Button kehrt in den „Active VM“ State zurück. Kann mehrere Minuten dauern.
der „Commit“-Button setzt die VM dauerhaft auf den per „Preview“ ausgewählten Snapshot, und löscht alle späteren/danach erstellten Snapshots. Wer im obigen Beispiel auf „snapshot 2“ wechselt (diesen also committed), verliert die Snapshots 3 und 4, Snapshot 1 und 2 bleiben erhalten.
Die VM ist jetzt wieder im „Active VM“ State.
Snapshot löschen¶
Nicht benötigte Snapshots können über den „Delete“-Button jederzeit gefahrlos und ohne Auswirkungen auf die VM gelöscht werden, sofern sie nicht verwendet werden (also nicht im „preview“ State sind). Die VM muss dazu nicht heruntergefahren werden - es tangiert sie einfach nicht.
Wer im obigen Beispiel Snapshot 1 löscht, behält noch Snapshot 2.
Backup und Restore¶
Clone vs Snapshot¶
Es gibt keinen Geschwindigkeitsunterschied zwischen dem Erstellen einer VM aus einem Snapshot oder dem Erstellen eines Clones.
Beim Snapshotting kann die VM weiterlaufen, was aber insbesondere bei DB-Servern trotz automatischer, kurzzeitiger Pausierung und Speicherung des Memory-Zustandes zu Inkonsistenzen führen kann. Diese Gefahr ist bei Cloning durch das geforderte Abschalten der VM ausgeschlossen.
VM-Backup¶
Zwei Möglichkeiten:
Manuell über eine Backup Storage Domain
Scriptbar per API
- Manuell
VMs lassen sich entweder als Clone oder als VM auf Basis eines Snapshots in eine Backup Storage Domain sichern. VMs in einer Backup Storage Domain sind immer ausgeschaltet und können dort auch nicht gestartet werden - dafür müssen sie importiert werden (siehe Restore).
Jede Data Storage Domain kann in ihren Eigenschaften per Checkbox zu einer Backup Storage Domain gemacht werden. Backup Storage Domains können an Datacenter attached oder von diesen detached werden, von daher eignen sie sich auch zum Austausch von VMs über Datacenter-Grenzen hinweg.
Backup Storage Domains sind (zumindest in der Theorie) schneller als Export-Domains, und es können mehrere davon vorhanden sein.
Tipp
Warum muss auf Basis eines Snapshots noch eine VM erzeugt werden? Antwort: die Snapshots wären verloren, wenn die Original-Maschine gelöscht werden würde.
Einmalig Data Domain zu einer Backup Storage Domain machen:
Storage > Domains > New Domain > Domain Function: Data, Advanced Parameters: „Backup“ auswählen
VM-Snapshot sichern:
VM kann weiterlaufen
Compute > Virtual Machines > virtuelle Maschine auswählen > Snapshot mit Memory-Zustand erstellen (VM wird damit kurz pausiert); als Description am besten den aktuellen Zeitstempel in der Form „2020-02-25 0910“ wählen
Detailansicht virtuelle Maschine > Snapshots Tab > Snapshot wählen > Clone, Name: „vmname-snapshot-2020-02-25-0910“
Es wird eine neue VM erstellt; dies benötigt Zeit.
Snapshot entfernen
VM-Clone sichern (empfohlen):
VM muss abgeschaltet werden
Compute > Virtual Machines > virtuelle Maschine auswählen > More Actions > Clone VM, Name: „vmname-clone-2020-02-26-1909“
Es wird eine neue VM erstellt; dies benötigt Zeit.
Original-VM starten
Egal ob VM-Snapshot oder ganzer VM-Clone: neu erstellte VM in die Backup-Domain exportieren.
Die neue VM muss ausgeschaltet bleiben.
Compute > Virtual Machines > virtuelle Maschine auswählen > Disks > More Actions > Move > Target > Backup Storage Domain
Optional kann de neue VM - allerdings ohne Disks (!!) - gelöscht werden.
Dauer/Zeiten bei einer VM mit einer 400 GB Disk, real 250 GB, Data Domain mit Gluster, Backup Domain auf NFS, alles 10 Gbps:
Erstellen der VM aus dem Snapshot / Erstellen des Clones 35 Minuten, Move der Disk in die Backup Domain 16 Minuten
- per API
Scriptbares Backup gegen das API, Pseudocode:
hole liste aller VMs für jede VM: erstelle einen snapshot clone eine neue VM auf basis dieses snapshots (dauert mind. 3 Minuten) exportiere den clone in die default export domain (z.B. NFS; dauert mind. 5 Minuten) wenn fertig, lösche den snapshot und die cloned VMAb 4.4 aufwärts können „Incremental Backups“ verwendet werden, was auf „Changed Block Tracking“ und dem NBD-Protokoll basiert. Es sind keinerlei Snapshots mehr nötig. Damit sieht der Backup-Workflow wie folgt aus:
API-Call startet ein komplettes Backup
Disk herunterladen (qcow2)
Beim nächsten Backup wird ein API-Call für das inkrementelle Backup abgesetzt
Nur die geänderten Blöcke werden heruntergeladen
Siehe auch https://www.youtube.com/watch?v=X-xHD9ddN6s
VM-Restore¶
Import von VMs aus einer Backup oder Data Storage Domain
Storage > Domains > VM Import > VMs auswählen > Import
Target Cluster und Storage Domain prüfen
vNic Profiles Mapping prüfen, evtl. „Reassign Bad MACs“-Checkbox nutzen
Ab oVirt 4.4 mit inkrementellen Backups:
wie vorher auch VM mit hochgeladener Disk erstellen
nur geänderte Blocks werden auf die Disk kopiert
Siehe auch https://www.youtube.com/watch?v=X-xHD9ddN6s
oVirt-Engine API¶
Ein paar Beispiele.
- Mögliche Befehle für eine VM auflisten
curl -X GET -k -u "$USERNAME:$PASSWORD" -i "https://$OVIRT_ENGINE/ovirt-engine/api/vms/$VMID"
- VMs auflisten, inkl. IDs
curl -X GET -k -u "$USERNAME:$PASSWORD" -i "https://$OVIRT_ENGINE/ovirt-engine/api/vms"
- VM starten/stoppen/rebooten
curl -X POST -k -u "$USERNAME:$PASSWORD" -H "Accept: application/xml" -H "Content-Type: application/xml" -i "https://$OVIRT_ENGINE/ovirt-engine/api/vms/$VMID/reboot" --data "<action/>"
- Global vergebene Tags auflisten
curl -X GET -k -u "$USERNAME:$PASSWORD" -i "https://$OVIRT_ENGINE/ovirt-engine/api/tags"
Quelle:
VM-Ex- und -Import¶
Import mit virt-v2v / virt-p2v¶
virt-v2v installieren und bei Bedarf „patchen“, so dass es ein anderes tmp-Verzeichnis verwendet (virt-v2v braucht temporären Space - oft viel mehr, als was tmpfs bietet. Das Setzen von TMPDIR in Bash bringt nichts):
dnf -y install virt-v2v virt-v2v-bash-completion
cp /usr/bin/virt-v2v /usr/bin/virt-v2v.orig
#!/usr/bin/sh
env TMPDIR=/backup/tmp /usr/bin/virt-v2v-original $@
virt-v2v setzt das python-ovirt-engine-sdk4 sowie ein installiertes und laufendes libvirtd voraus.
- Ziel: oVirt / RHV
Direkter Upload einer OVA in oVirt/RHV (ab oVirt 4.2). Hierbei auf Kompatibilitäten achten - es hilft, virt-v2v in einer Umgebung zu verwenden, die die gleiche OS-Version wie das Zielsystem fährt.
virt-v2v -i ova . -o rhv-upload -oc https://ovirt-engine.example.com/ovirt-engine/api -of raw -op /path/to/ovirt/password-file -os STORAGEDOMAIN -oo rhv-cafile=/path/to/ovirt-engine/ca.pem -oo rhv-cluster=CLUSTERNAME
Unbedingt die Details zu den Paramatern aus https://libguestfs.org/virt-v2v-output-rhv.1.html entnehmen
- Ziel: OVA in qcow2 konvertieren
Eine lokal vorliegende OVA in eine qcow2-Disk umwandeln:
mkdir -p /images/converted virt-v2v -v -i ova vm.ova -o local -os /path/to/output-dir -of qcow2
Import einer OVA (OVF)¶
OVA-Dateien können im oVirt-GUI unter Compute > Virtual Machines direkt importiert werden.
Liegt die zu importierende Appliance in Form mehrerer Dateien vor (.ova, .vmdk, .mf, .nvram), diese einfach mit tar zusammenfassen und der tar-Datei die Endung .ova verpassen. Tools wie das proprietäre ovftool von VMware sind nicht nötig.
Import aus VMware¶
Wie kann eine Migration von VMware nach oVirt so gelingen, dass möglichst wenig Hardware investiert werden muss und der Betrieb nicht komplett ausser Gefecht gesetzt ist?
Die Situation:
Die Migration soll möglichst ohne Big Bang oder Parallel-Anschaffung eines neuen Hardware-Clusters auskommen. Netz-Design wird übernommen.
Es sind n VMware ESXi-Hosts vorhanden; die Server stellen gleichzeitig den SSD-basierten Storage für die VMs bereit (also ein klassisches Hyperconverged Setup). VMware vSphere ist installiert, allerdings ohne HA-Lizenz.
Ein physisches NAS mit ausreichend Speicherplatz und 10 Gbps-Anbindung ist vorhanden.
Der Ablauf:
Einen neuen Host anschaffen. Darauf CentOS und oVirt installieren.
NFS-Storage für die kommenden temporären Data- und Hosted-Engine Storage-Domain auf dem NAS vorbereiten und per NFS freigeben.
Die VMs werden aus VMware vSphere in oVirt importiert und durch den neuen oVirt-Host ausgeführt. Dank vSphere-Lizenz für oVirt kein Problem. Die Disks der VMs werden dabei per NFS auf dem NAS abgelegt.
Ab hier Point of no return: Ist VMware bis auf die vSphere-VM leergeräumt, werden die nun arbeitslosen ESXi-Hosts mit CentOS überbügelt und als oVirt-Hosts in den neuen Cluster-Verbund aufgenommen.
Danach wird auf den oVirt-Hosts Gluster installiert und konfiguriert. Benötigt wird ein Volume für die Hosted-Engine sowie mindestens ein Data-Volume für die VMs. Der heikelste Teil, besonders bei den Arbeiten am Dateisystem des ersten oVirt-Hosts.
Am Ende werden die Disks der VMs vom NAS auf Gluster verschoben. Da das für die oVirt-Engine nicht ganz so einfach funktioniert, wird sie in ihrer Gluster Storage-Domain neu aufgesetzt.
Die längste Downtime verzeichnen die VMs während des Exports aus VMware und dem Import in oVirt.
Import aus VMware vCenter¶
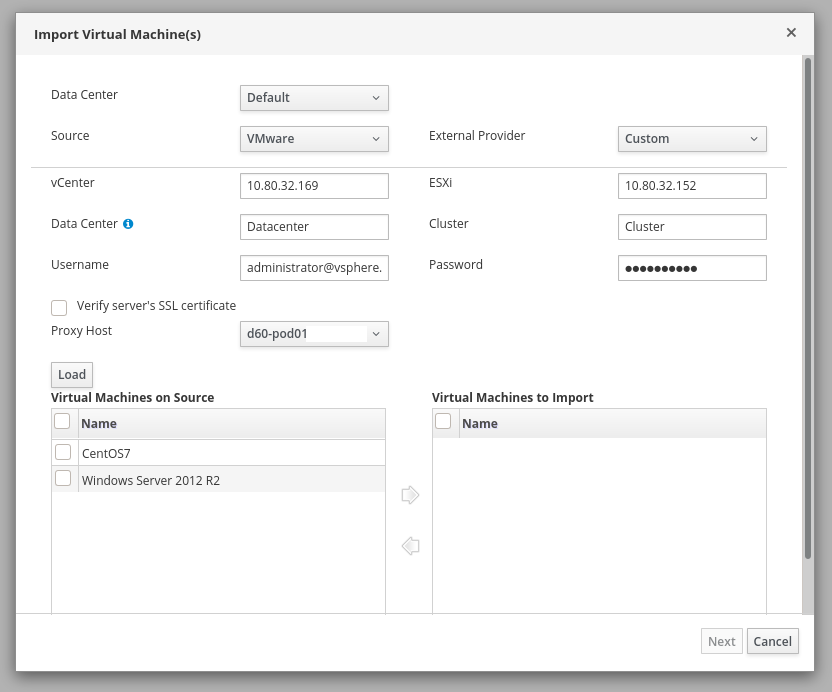
Import virtueller Maschinen aus VMware¶
Für den Import einer VM direkt aus VMware muss es mindestens ein vCenter sein; ein einfacher ESXi reicht nicht aus. Grund: das verwendete virt-v2v redet nicht mit den ESXi-Hosts.
Der Import wird vom vdsm durchgeführt; Logs finden sich auf dem Host, der den Import durchführt, unter tail -f /var/log/vdsm/import/*. Dort lässt sich auch der Import-Fortschritt in Prozent beobachten. Die Disks werden auf Wunsch Thin Provisioned importiert. Der Import-Vorgang benötigt allein ca. 30 Minuten, um die VM zu validieren und vorzubereiten, bevor deren Disks schrittweise von VMware in oVirt überführt werden.
Der Import kann je nach Backend und Netzwerkkonfiguration durchaus ewig dauern: 15h für 400G Disk (180 GB thin) sind möglich. Geduld haben.
Achtung
oVirt/VDSM beschwert sich, dass die Boot-Partition zu wenig freien Festplattenplatz aufweist? Anmeldung in der VM ist nicht möglich, das Passwort stimmt nach dem Import nicht mehr? Veraltete Daten? Snapshots in VMware entfernen - die VMs werden im Status vor ihren Snapshots importiert.
CentOS: installierte VMware Guest-Tools (open-vm-tools) werden automatisch entfernt.
Bei Windows-VMs unbedingt VOR dem Import die VMware-Tools deinstallieren. Nach dem Import lassen sie sich nicht mehr entfernen und stören bei jedem Reboot.
Zu importierende VM in VMware herunterfahren. In der oVirt-Engine unter „Compute > Virtual Machines > Import > Source: VMware“ folgende Details angeben:
vCenter: IP-Adresse/Hostname der vCenter-Engine
ESXi: IP-Adresse/Hostname des ESXi-Hosts, auf dem die zu importierende VM läuft
Data Center: Hierarchie/Name des VMware-Datacenters, z.B. „prod/datacenter“
Cluster: Name des VMware-Clusters
Beim Import darauf achten:
Leerzeichen im Servernamen entfernen
die richtige Storage Domain auswählen
Nach dem Import
Typ der virtuellen Maschine ändern (Desktop > Server)
die Memory-Settings anpassen
die Netzwerkkarten der virtuellen Maschinen entfernen, neue hinzufügen und konfigurieren (damit die MAC-Adresse sowie der Typ der Netzwerkkarte zu oVirt passen)
die oVirt-Guest-Tools installieren
Import aus KVM¶
oVirt verwendet den User vdsm, um den Import durchzuführen.
WICHTIG: der Benutzer „vdsm“ muss ein ssh-keygen auf einem oVirt-Host ausführen, per ssh-copy-id auf den KVM-Server kopieren und den Login mit ssh testen (vor allen Dingen den Erst-Kontakt mit „yes“ bestätigen).
In der Weboberfläche:
Compute > Virtual Machines > Import > Source: KVM (via libvirt)
URI: Adressiert werden muss KVM mit „qemu+ssh://root@ip/system“
Proxy Host: den Host angeben, auf dem der vdsm-User den SSH-Key auf den kvm kopiert hat
Siehe auch https://www.mail-archive.com/users@ovirt.org/msg46161.html
Export nach KVM¶
VM aus oVirt ex- und in KVM importieren:
zu exportierende VM ausschalten
der Disk eine Beschreibung geben
in der oVirt-Oberfläche Rechtsklick auf die VM > „Export to OVA“
auf einem der Hosts speichern (ergibt eine thin provisioned OVA-Datei)
in KVM importieren (dafür muss die OVA-Disk vorher umgewandelt werden: enttaren und die enthaltene VMDK in QCOW2 umwandeln)
Maintenance¶
Maintenance Mode¶
- Global Maintenance Mode einschalten
Wird zur Pflege der oVirt-Engine und komplette Reboots benötigt. Der HA-Agent stoppt damit die Überwachung der Engine-VM. Am sichersten auf dem Host ausführen, auf dem die oVirt-Engine läuft:
hosted-engine --set-maintenance --mode=global; sleep 60
- Global Maintenance Mode abschalten
hosted-engine --set-maintenance --mode=none
Danach startet die oVirt-Engine mit ein paar Minuten Verzögerung automatisch.
- Local Maintenance Mode einschalten
Wird zur Pflege einzelner Hosts auf den Hosts selbst verwendet. Wird ein Host in den Maintenance-Mode versetzt, werden dessen Gäste auf andere Hosts wegmigriert. Entweder über das Web-GUI > Host > Maintenance, oder per Kommandozeile auf dem Host ausführen, der in den Maintenance-Mode geschickt werden soll:
hosted-engine --set-maintenance --mode=local
- Local Maintenance Mode abschalten
hosted-engine --set-maintenance --mode=none
oVirt herunterfahren¶
Shutdown. Allgemein gilt die (logische) Reihenfolge:
VMs stoppen
oVirt stoppen
Gluster stoppen
Maschinen stoppen
oVirt herunterfahren und ausschalten. Dauer ohne Backup ca. 20 Minuten.
ITEM |
CONDITION |
STEP |
|---|---|---|
1 |
Gluster-Nodes |
Auf einem Gluster-Node für jedes Gluster-Volume prüfen: |
2 |
Shards? |
Healing starten und warten, bis es abgeschlossen ist: |
3 |
Alle VMs im oVirt per „Shutdown“-Knopf herunterfahren, ausser der oVirt-Engine (HE). |
|
4 |
Warten, bis alle VMs down sind. |
|
5 |
Bei Bedarf Backups in die Export- oder Backup-Domain durchführen. |
|
6 |
Global Maintenance Mode setzen: |
|
7 |
Warten, bis |
|
8 |
Nur Hypervisor-Node |
Alle Hosts herunterfahren, die kein Gluster-Node sind und die keine oVirt-Engine ausführen können: |
9 |
Auf dem Host, der die oVirt-Engine aktuell ausführt (siehe |
|
10 |
Warten, bis |
|
11 |
Auf allen Hosts die Locks auf dem Shared Storage entfernen: |
|
12 |
Alle Hosts herunterfahren, die kein Gluster-Node sind:
|
|
13 |
Gluster-Nodes |
Gluster-Prozesse graceful stoppen - auf jedem Gluster-Node nacheinander: |
14 |
Gluster-Nodes |
Alle Gluster-Nodes einen nach dem anderen herunterfahren: |
15 |
Möglicherweise läuft der Gluster-Storage Unmount auf dem Host, der usprünglich Gluster gemountet hat, in einen Timeout (bis zu 10 Minuten) und wird dann gekillt. Kein Grund zur Panik. Einfach warten |
oVirt hochfahren¶
Startup kann 5 bis ca. 30 Minuten dauern. Allgemein gilt die Reihenfolge:
Maschinen starten
Gluster starten (startet automatisch) und prüfen
oVirt starten
VMs starten
ITEM |
CONDITION |
STEP |
|---|---|---|
1 |
Gluster und oVirt getrennt? |
|
2 |
Gluster startet automatisch. |
|
3 |
Gluster-Nodes |
Auf einem der Gluster-Nodes für jedes Gluster-Volume prüfen: |
4 |
Shards? |
Healing starten und warten, bis es abgeschlossen ist: |
5 |
Auf den oVirt-Hosts: sind alle Gluster-Bricks gemountet? Ist der |
|
6 |
Auf einem möglichen oVirt-Engine-Host: |
|
7 |
Ein paar Minuten warten, bis die Meldung kommt: „!! Cluster is in GLOBAL MAINTENANCE mode !!“ |
|
8 |
|
|
9 |
Die Hosted Engine ist erreichbar, wenn |
|
10 |
Im oVirt unter „Storage Domains“ den Status der Storage Domains anschauen. Manchmal sind die Storage Domains nach dem Startup für vier bis fünf Minten online, um dann für fünf Minuten wieder offline zu gehen - bis oVirt sich eingependelt hat. Einfach 5 bis 15 Minuten abwarten. Wirklich: warten. |
|
11 |
Die VMs starten nicht von selbst und müssen von Hand hochgefahren werden. |
Upgrade¶
Allgemein¶
Beschreibt das Upgrade eines Hosted-Engine Setups.
Zunächst ein Backup der Hosted-Engine ziehen, anschliessend den Global Maintenance Mode aktivieren.
Auf der Hosted Engine:
yum updatedurchführen. Damit werden auch die für die Engine relevanten Pakete upgedatet:ovirt-engine-dwh-setup
ovirt-engine-setup
ovirt-engine-setup-plugin-websocket-proxy
engine-setupausführen. Das Setup stellt die von der Installation bekannten Fragen, und bietet die dort getätigten Antworten als Default-Antwort an.Reboot der Hosted Engine auf dem Host, der sie zuletzt gehostet hat:
hosted-engine --vm-shutdownhosted-engine --vm-start
Anschliessend den Global Maintenance Mode beenden.
Danach kommen die oVirt-Hosts einzeln an die Reihe. Die Hosts am einfachsten über die oVirt-Weboberfläche updaten (das Upgrade über die Weboberfläche kümmert sich auch um Kernel-Updates etc.). Jeden Host einzeln, und jeden Host-Reboot sauber abwarten. Bei einem Hyperconverged Setup auf Basis von Gluster erst mit dem nächsten Host weitermachen, wenn gluster volume heal $DATADOMAIN info | grep 'entries' | grep -v 'entries: 0' keine Einträge zurückliefert.
VMs auf andere Hosts moven.
Einzelnen Host in Maintenance Mode versetzen
Installation > Upgrade
Nach dem Reboot des Hosts: Management > Activate
4.3 > 4.4¶
Vor dem Upgrade auf 4.4 muss zuerst auf 4.3 latest aktualisiert werden. Ein Upgrade von 4.1 auf 4.3 wird nicht unterstützt. Ein anschliessendes Rollback ist unmöglich - hier hilft nur, auf ein Backup der oVirt-Engine zurückzugreifen.
Ein Gluster-Upgrade ist davon unabhängig und muss bei Bedarf separat durchgeführt werden.
Siehe auch https://www.youtube.com/watch?v=JlDmpAtActc
Troubleshooting¶
- Alle relevanten Log-Files auf einem Host anzeigen
tail -f /var/log/messages /var/log/openvswitch/*.log /var/log/ovirt-hosted-engine-ha/*.log /var/log/ovirt-imageio-daemon/*.log /var/log/rhsm/*.log /var/log/sanlock.log /var/log/vdsm/*.log /var/log/vdsm/import/*.log
- Host, auf dem die Hosted Engine lief, ist im Non-Operational-State?
Restart der Hosted-Engine High Availability Services mit
systemctl restart ovirt-ha-agent; systemctl restart ovirt-ha-broker- Storage Connection wegen Timeout weg, und man will sie wiederherstellen?
VMs vom Host wegnehmen, Host in Maintenance Mode schicken, Reboot, und Host wieder aktivieren.
- „Cannot add Host. Connecting to host via SSH has failed, verify that the host is reachable (IP address, routable address etc.) You may refer to the engine.log file for further details.“
Trat beim Deploy der Hosted Engine auf. Die oVirt-Engine versucht sich per SSH auf den Host zu verbinden (nicht umgekehrt, wie man vielleicht annehmen könnte). In unserem Fall war der Host sshd-seitig zu streng konfiguriert (siehe /var/log/secure).
- „fatal: [localhost]: FAILED! => {„ansible_facts“: {„ovirt_hosts“: []},“attempts“: 120,“changed“: false,“deprecations“: [{„msg“: „The ‚ovirt_hosts_facts‘ module is being renamed ‚ovirt_host_facts‘“, „version“: 2.8}]}“
Für oVirt 4.2.8 musste neben CentOS 7.6 auch Ansible auf 2.7.10 gepinnt werden. Andere Lösung:
hosted-engine --deploy --noansible- ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine.config.vm ERROR Unable to identify the OVF_STORE volume, falling back to initial vm.conf. Please ensure you already added your first data domain for regular VMs
Lösung: https://access.redhat.com/solutions/3892791. Es hilft aber auch: Storage > Domain > hosted_storage > Update OVFs
- VM ‚xxx‘ is down with error. Exit message: Unable to get volume size for domain <VG_ID> volume <LV_ID>.
oVirt gerade neu gestartet? Falls ja: Der Storage ist noch nicht soweit, selbst wenn er zeitweilig als online angezeigt wird. 5 bis 15 Minuten Zeit geben und abwarten, danach noch einmal probieren.
- The hosted engine configuration has not been retrieved from shared storage. Please ensure that ovirt-ha-agent is running and the storage server is reachable
10 bis 30 Minuten abwarten. Danach:
systemctl status -l ovirt-ha-agent journalctl -u ovirt-ha-agent systemctl start ovirt-ha-agent tail -f /var/log/ovirt-hosted-engine-ha/agent.log gluster peer info gluster volume info hosted-engine --connect-storage
- oVirt 4.2.2: ein neuer Host lässt sich nicht hinzufügen. Es scheitert an der Erstellung der Netze, der Host bleibt ständig in einer Schleife „Activating - Non-Operational“ hängen.
Vor dem Deploy unter „Compute > Cluster > Logical Networks“ > Button „Manage Networks“ alle Netze auf „nicht required“ setzen (bis auf oVirt Management). Nach Hinweis aus https://lists.ovirt.org/pipermail/users/2018-April/088430.html
- Hosted Engine kann nicht auf einen neuen Host migriert werden? „No available Host to migrate to.“?
Beim Hinzufügen des Hosts unter „New Host > Hosted Engine“ die „Choose hosted engine deployment action“ auf „Deploy“ setzen.
- Beim Einrichten der (Hosted-)Engine und dem Storage, z.B. Gluster: „[Error creating a storage domain]“.
Grund könnte ein Gluster Read-only Filesystem oder ein fehlendes
gluster volume start ...sein.- Unable to upload image to disk due to a network error. Make sure ovirt-imageio-proxy service is installed and configured, and ovirt-engine’s certificate is registered as a valid CA in the browser.
Passiert bei Upload einer Disk unter Storage > Disks > Upload. Liegt daran, dass Firefox das oVirt-Engine CA-Zertifikat nicht importiert hat und deshalb keine Verbindung zum ovirt-imageio-daemon aufbauen kann. Der Trick: im Upload-Dialog „Test Connection“ auswählen, in der erscheinenden Fehlermeldung das per Link angebotene CA-Zertifkat herunterladen, und in Firefox als Authority importieren. Danach klappt auch der Upload.
Built on 2026-04-15